Why Unicode
The exchange of data between systems with incompatible character sets can also lead to problems.
The solution to this problem is the use of a character set that includes all characters at once. Unicode provides this ability. A variety of Unicode character representations are possible for the Unicode character set (for example, UTF, in which a character can occupy between 1 and 4 bytes).
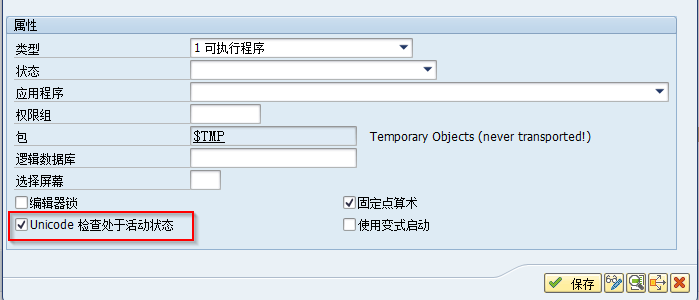
ABAP 7.5开始,程序必须是Unicode兼容的程序
在SAP ABAP程序的属性中必须勾选“Unicode检查处于活动状态”,否则无法激活程序。
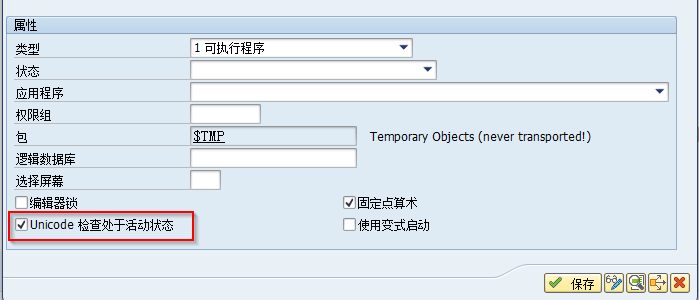

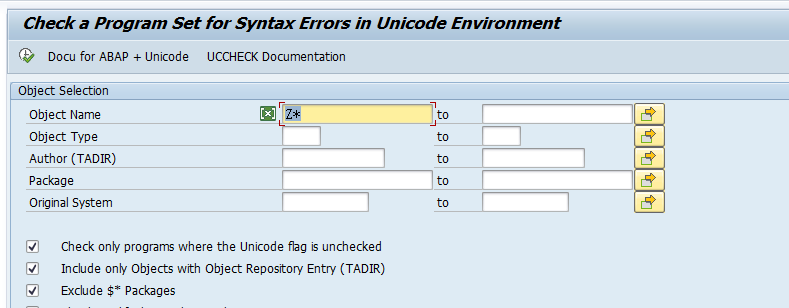
检查程序是否兼容Unicode
在SAP系统中,可以用事物代码UCCHECK,可以按程序名或者按开发类(包)。
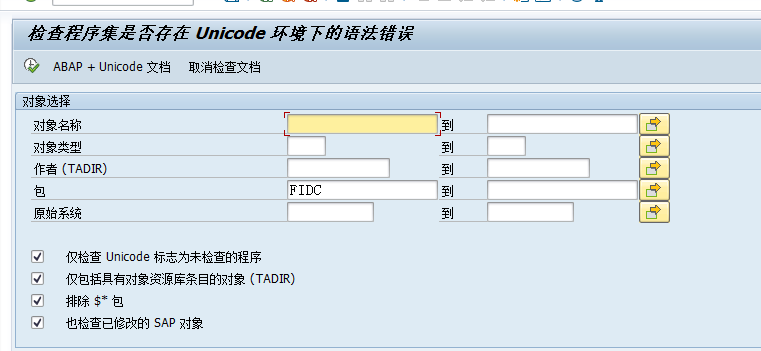

检查SAP系统是否支持Unicode
Prior to release 6.10, SAP supported different codes for representing characters of different fonts, such as ASCII, EBCDIC.
If you have developed on SAP releases 6.20 or later, all SAP implementations will be running Unicode-compliant systems.
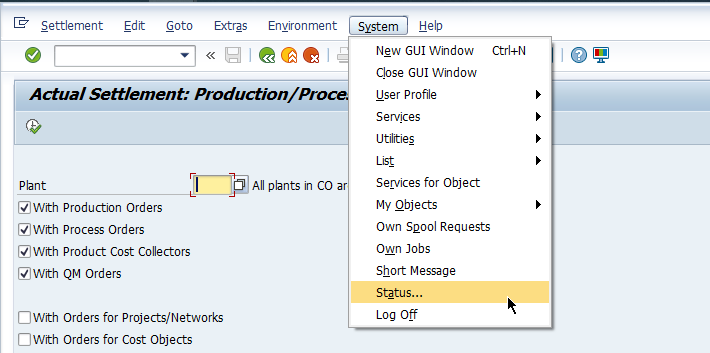
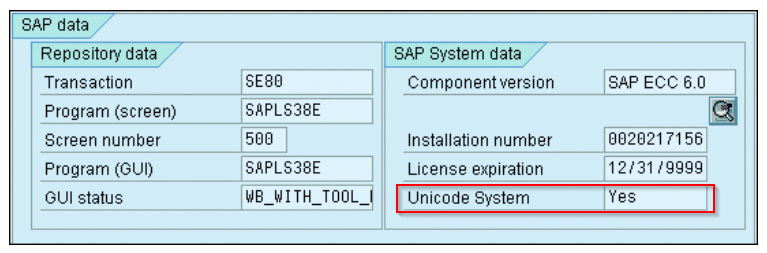
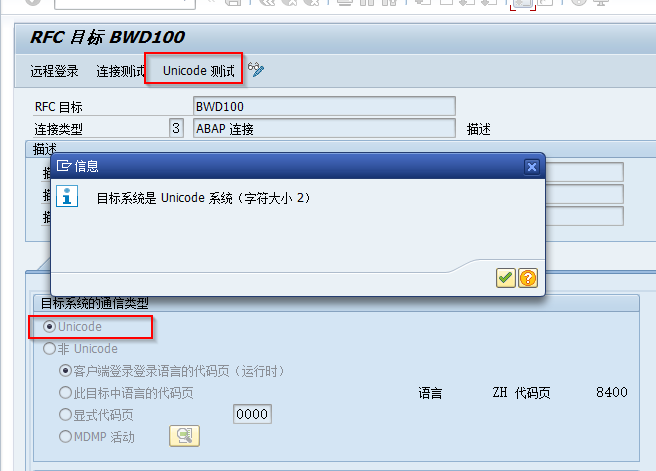
SM59检查SAP Destination是否兼容Unicode
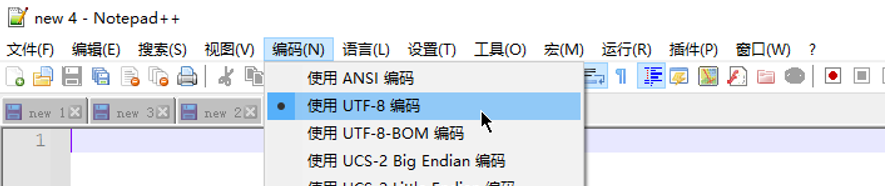
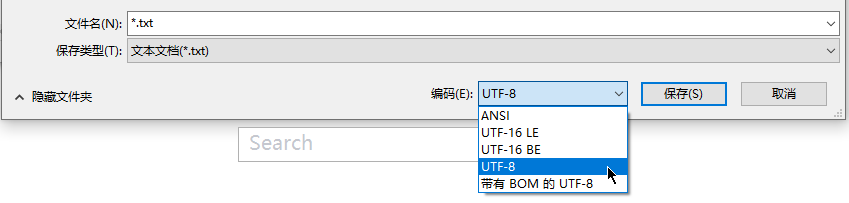
Notepad++和记事本保存文件为UTF编码格式
文本文件转换编码格式前最好先备份一份,以免转换出问题导致原文件也坏了。
Txt文本默认是ANSI编码,从SAP中复制或导出的某些信息是UTF8,ANSI兼容性没有UTF8好,因此需另存为UTF8格式,否则下次打开就乱码了。
UTF-8不需要BOM来表明字节顺序,但可以用BOM来表明编码方式。字符”ZERO WIDTH NO-BREAK SPACE“的UTF-8编码是EF BB BF。所以如果接收者收到以EF BB BF开头的字节流,就知道这是UTF-8编码了。
在utf-8编码文件中BOM在文件头部,占用三个字节,用来标识该文件属于utf-8编码,现在已经有很多软件识别BOM头,但还是有些不能识别BOM头,比如PHP就不能识别BOM头,这也就是用记事本编辑utf-8编码的PHP文件后,就会报错的原因。
在windows环境下,用记事本打开任何一个文本文件,另存为utf-8格式后,这样文件就自动被加上了BOM头信息。可以很明显的看出,含BOM头的文件多出三个字节 efbbbf。notepad++会自动添加为带Bom的utf8。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,又称万国码,由Ken Thompson于1992年创建。现在已经标准化为RFC 3629。UTF-8用1到6个字节编码Unicode字符。用在网页上可以统一页面显示中文简体繁体及其它语言(如英文,日文,韩文)。
SAP程序转换到Unicode
In a Unicode system, only Unicode programs can be executed.
A syntactically correct Unicode program will normally run with the same semantics and the same results in Unicode and non-Unicode systems.
# RZ10开启Unicode检查
abap/unicode_check = ON
注意:本身就是Unicode的系统,这个参数默认是OFF的(本身就是Unicode,默认强行检查,没必要再显式开启),但是ABAP程序依旧会检查Unicode兼容性,也不必人工去开启。本身不是Unicode系统的SAP系统,开启这个选项后才能执行下面的Unicode检查,但开启后要尽快优化那些不兼容Unicode的程序,否则会影响业务。
# 勾选程序属性中的Unicode检查
# 使用事物代码UCCHECK对要转换的程序进行Unicode兼容性检测
如果检测结果中有不兼容的程序,按照提示信息优化即可(不存在自动转换的功能,你需要根据检查结果人工去适配)。
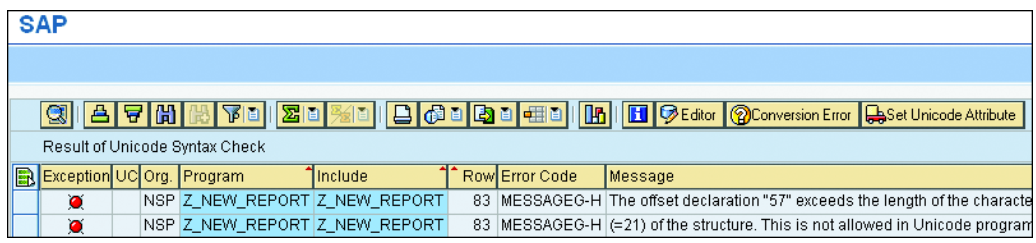
ABAP中的CHAR类型和Byte类型
在SAP ABAP中,CNDT和String是CHAR类型,可以直接转换,否则会报Unicode错误。
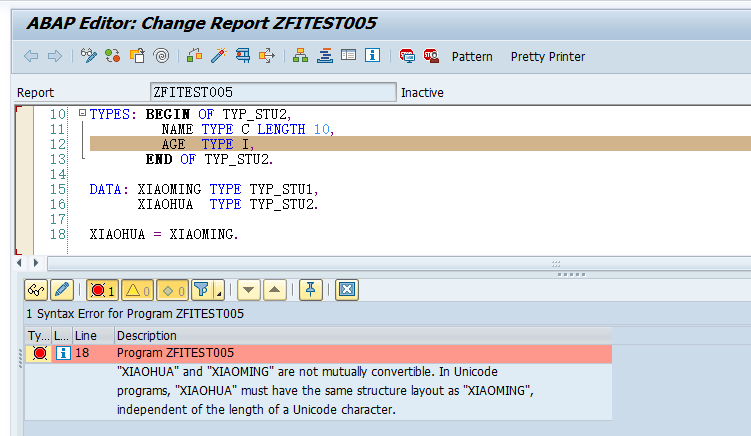
In Unicode programs, elementary data objects of types X and XSTRING are byte types. In non-Unicode programs, data objects of this type are generally handled as character types. Byte类型的操作也与C类型不尽相同,需要特殊的函数序列换和反系列化。
Xstring到string,以及反向操作的几个函数:SCMS_STRING_TO_XSTRING,SCMS_XSTRING_TO_BINARY,SCMS_BINARY_TO_STRING。也可以用类CL_BCS_CONVERT,方法比较多。
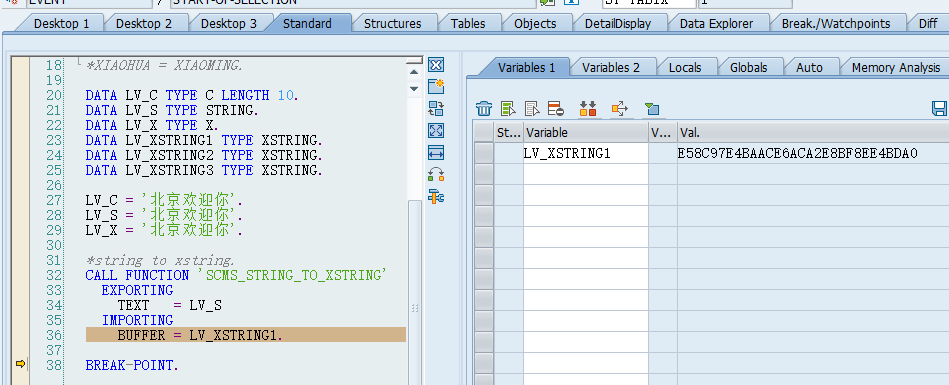
求字数和求字节数可分别使用strlen关键字和CL_ABAP_LIST_UTILITIES=>DYNAMIC_OUTPUT_LENGTH方法。

也可用DESCRIBE关键字,但需要指定MODE。

也可以分别使用STRLEN计算C类型的长度,XSTRLEN计算Byte string的长度。
STRING和CHAR最主要的差别是CHAR定长但STRING不定长,因此STRING常用于与不靠谱的外围系统接口字段中(如果接口字段比传进来的数据段,数据会被截取)。
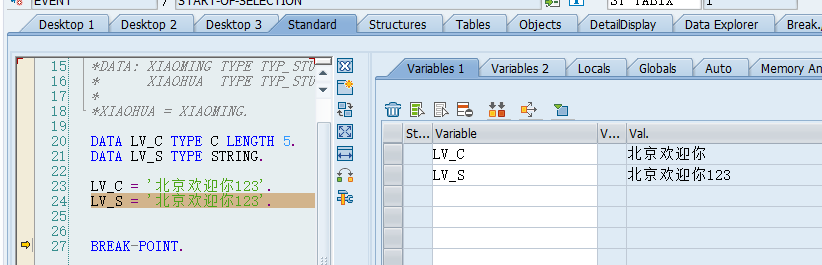
Languages, Code Pages, and Conversions
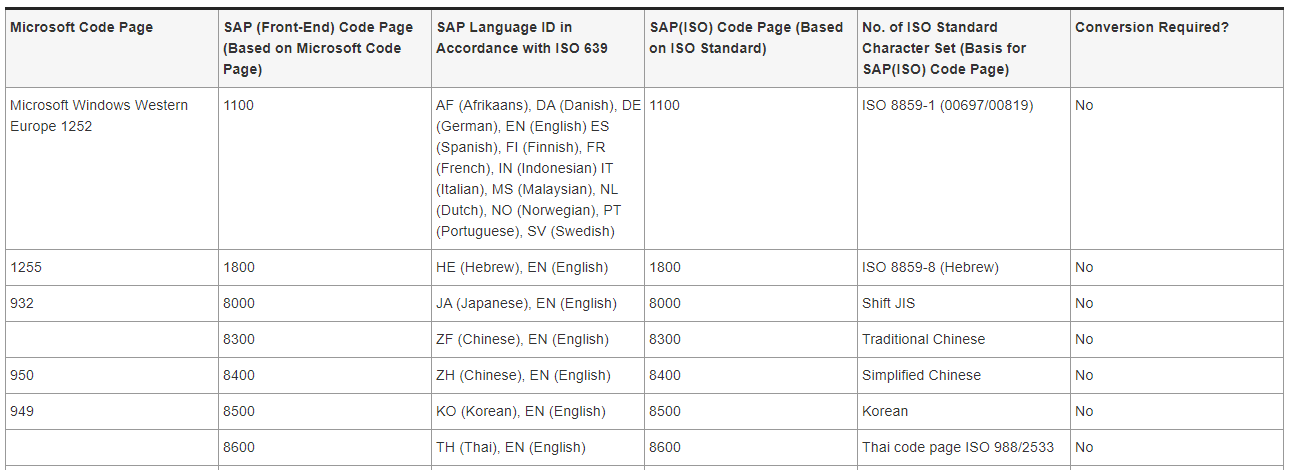
The following table shows some of the ISO code pages in the SAP system for an SAP system without Unicode character sets and the appropriate Microsoft (ANSI) code pages used for communication with Microsoft programs. If the numbers of the appropriate SAP(ISO) code pages and SAP(front-end) code pages differ, data must be converted.
The table does not contain all possible code pages and blended code pages. For a more comprehensive overview, see, for example, SAP Note 73606.
Any language code you want to use must be activated in the system via transaction I18N -> I18N Customizing -> I18N System configuration.
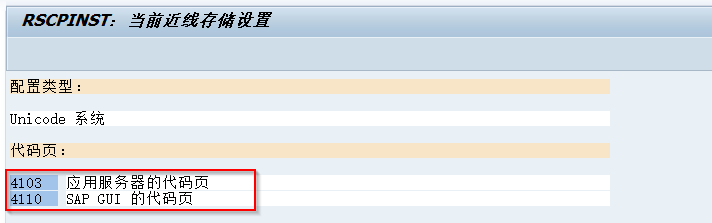
You can check if your SAP application server is using Little Indian (4103) or Big Indian (4102) via t-code I18N -> I18N Customizing -> I18N System Configuration -> Display Current NLS config -> “Code Page of Application Server”.
# Common Encoding/Code Pages
1100 for ISO-8859-1, which is similar to WINDOWS-1252/ANSI
4110 for UTF-8, the optional BOM (Byte Order Mask) will be EFBBBF for UTF-8
4102 for UTF-16be
4103 for UTF-16le
8400 for GB2312
# UTF-8, UTF-16, UTF-16LE, UTF-16BE的区别
首先, 我们说的unicode, 其实就是utf-16, 但最通用的却是utf-8。
SAP系统默认的unicode采用的是4103(即UTF-16le),4103编码兼容8400(GB2312)和其他绝大多数编码集,因此SAP服务器端编码为万能编码4103,用户端编码根据用户电脑环境进行设置。
原因: 我猜大概是英文占的比例比较大, 这样utf-8的存储优势比较明显, 因为utf-16是固定16位的(双字节), 而utf-8则是看情况而定, 即可变长度, 常规的128个ASCII只需要8位(单字节), 而汉字需要24位
UTF-16, UTF-16LE, UTF-16BE 及其区别BOM
同样都是unicode, 为什么要搞3种这么麻烦?
先说 比较好理解的, 俗称大头
比如说char ‘a’, ascii为
0x61, 那么它的utf-8, 则为 [0x61], 但utf-16是16位的, 所以为[0x00, 0x61]
再说UTF-16LE(little endian), 俗称小头, 这个是比较常用的
还是char ‘a’, 它的代码却反过来: [0x61, 0x00], 据说是为了提高速度而迎合CPU的胃口, CPU就是这到倒着吃数据的, 这里面有汇编的知识, 不多说
然后说UTF-16, 要从代码里自动判断一个文件到底是UTF-16LE还是BE, 对于单纯的英文字符来说还比较好办, 但要有特殊字符,
图形符号, 汉字, 法文, 俄语, 火星语之类的话, 相信各位都很头痛吧, 所以, unicode组织引入了BOM的概念, 即byte order mark, 顾名思义, 就是表名这个文件到底是LE还是BE的, 其方法就是, 在UTF-16文件的头2个字节里做个标记: LE [0xFF, 0xFE], BE [0xFE, 0xFF].
Unicode编码和非Unicode编码对ABAP程序的几个要求
# Include structure中的char类型只能是CNDT,string由于是边长类型不允许。
# In a non-Unicode system, you must specify both the byte order and the code page when opening a file (dataset).
# In a Unicode system, you must specify the ENCODING addition when opening a file (dataset).
本文作者: GavinDong
版权属于: GavinDong博客
文章链接: https://gavindong.com/9767.html
如果使用过程中遇到问题,可 **点击此处** 交流沟通。
版权所有,转载时必须以链接形式注明作者和原始出处及本声明。