An often asked question is how to get data into Hana as there are so many different options. Let me try to differentiate the various methods from a technical point of view.
Standalone products:
- SAP Data Services
- SAP LT Replication Server (SLT)
- Sybase Replication Server (SRS)
- Direct Extractor Connection (DXC)
- SAP Process Orchestration/Integration (SAP PI, SAP XI)
- SAP BW
and the Hana options:
- Hana Smart Data Access (SDA)
- Hana Smart Data Integration (SDI)
- Hana Smart Data Streaming (SDS)
The first and most important point to consider here is the question itself: How to get data into Hana. If Hana is just one of many sources and targets or there is no Hana in the picture at all, then the standalone products do make more sense. Or to argue into the reverse direction, there are so many different options because of the non-Hana scenarios. Okay, it would be odd if the standalone solutions can load everything but Hana, hence they have that capability as well which creates that confusion.
Example: My task is to integrate various system, the sources are an SAP ERP system, 5 Oracle databases, flat files of various formats, SQL Server,… and to load that into Teradata, Oracle and BW on Hana.
So Hana plays no or a little role in it, sounds like a perfect SAP Data Services scenario. Many sources, many targets and Data Services in the middle.
Hana is the sole target
A few years ago, if a customer wanted to load e.g. flat files into Hana, he had to install Data Services. A full blown ETL tool just to load a few files from Mainframe (Cobol Copybook), CSV files with a non-default format and other sources. Only Data Services as an ETL tool provides reading capabilities of essentially every source system, allows the data to be transformed easily so it can be loaded into the target structures. An installation of a full blown ETL tool just for that.
If realtime is required as well, then SLT or SRS would have to be installed in addition.
In case the source data should be just made available and not copied – the federated/virtual data model use case – SDA would need to be configured as well.
So at the end, for an e.g. SQL Server database as source, three products are needed. All with their own install, with their own connector to the source, totally different look and feel and different capabilities.
- Customer wants to perform Data Services like transformations in Realtime? Not possible.
- Customer wants to perform Data Services like transformations in a CalcView for virtual data models? Not possible.
- Customer wants to tryout one style, e.g. a virtual data model and then switch to batch data integration for performance reasons and then to realtime data integration for accuracy? No way.
- Customer wants to administer, maintain and monitor all from Hana? No chance.
- Customer wants to read from something less common, say MySQL? Only Data Services has that possibility.
For these reasons the Hana EIM Option Smart Data Integration was developed. Take the best concepts of all the products, merge those with existing Hana features and quickly you can develop the most powerful and easy to use product from ground up. Yes, SDI does not reuse any code from the old products.
Essentially, SDI is an extension of SDA which enhances it by
- Adapters
- Running outside of the Hana kernel – hence are not a stability threat for Hana
- Provide an Adapter SDK to write new adapters easily – every customer has a few common sources SDI provides adapters for plus one exceptional. They can write a new adapter for that within hours/days.
- Support onpremise and cloud deployments – a Hana cloud can read onpremise data as if it was local
- Realtime Push
- Adapters do support select and insert/update/delete but also a realtime push of change data
- Transformations
- All Data Services and Hana transformations are available in Hana natively
- UIs
- A Data Services like UI for the assembly of dataflows and the configuration of the individual transforms
- Supports batch reading, realtime transformations and virtual data models
- Hana Cockpit for monitoring and administration
The various SDI adapters
Ideally one source would have one adapter. One Twitter adapter to read Tweets. One Facebook adapter to read Facebook posts. One Oracle adapter to read Oracle data.
Some sources do provide different APIs to get data, especially when it comes to realtime. Take Oracle as a first example. To read from it executing SQL selects via JDBC is sufficient. But JDBC certainly does not support realtime. What are the realtime options for Oracle?
- Adding triggers to the source tables manually
- Oracle CDC API creating triggers internally
- Oracle CDC API using streams technology
- Oracle Streams used directly
- Oracle GoldenGate
- Oracle LogMiner
It does not make sense to have one adapter supporting all options or one adapter per realtime method. Hence the SDI OracleLogReader adapter is using the LogMiner technology for realtime plus the JDBC driver for normal reads.
Later we might add more adapters to support other realtime APIs as well, in case these are preferred by a customer.
SAP ERP is another example where multiple technologies could be used. There is certainly no JDBC driver for SAP ERP, so even reading tables is a challenge already.
- ABAP Adapter: Reads SAP tables via ABAP, also can read from Extractors and call BAPIs.
- ECCAdapter: This is a variant of a database adapter, so it does use the database transaction log to get the changes for realtime. But returns the data in the ABAP datatypes and deals with pool/cluster tables correctly.
- SLT Adapter?? This one is missing as of today. Would totally make sense to utilize SLT and its trigger based realtime approach to get the changes from ABAP tables. see ideaplace to vote up if you agree.
What is the best method for loading Hana?
As the goal of SDI was to provide a one stop solution for all Data Integration problems with Hana, the correct answer should be SDI. Only SDI …
- supports Batch and Realtime and Virtual access
- is fully integrated with Hana development UIs
- is integrated with Hana Monitoring Cockpit
- allows virtual table access (SDA) to its sources
- provides access to a large number of different sources, databases, SAP systems, applications, cloud apps, internet sources,…
- supports cloud and onpremise deployment options without any compromise
- does even support realtime transformations
- simplifies delta loads thanks to the realtime push of change data
- allows complex transformations to be performed easily (Data Services like)
- is using Hana repo for moving-to-production
- …
Also keep in mind, there are certain features missing as of today (SPS11), like Workflows. This is high on the priority list. The product was first delivered with Hana SPS09 which is relatively young compared to all others.
But again, SDI is the supposed optimal solution only because we have reduced the question to “loading into Hana”.
There are more than enough use cases, even in the Hana world where other tools have the edge.
SAP Data Services
For Data Integration from many to many systems with all the requirements related, Data Services is and will be a good choice. Its focus is on batch performance, transformations and connectivity to every possible source/target.
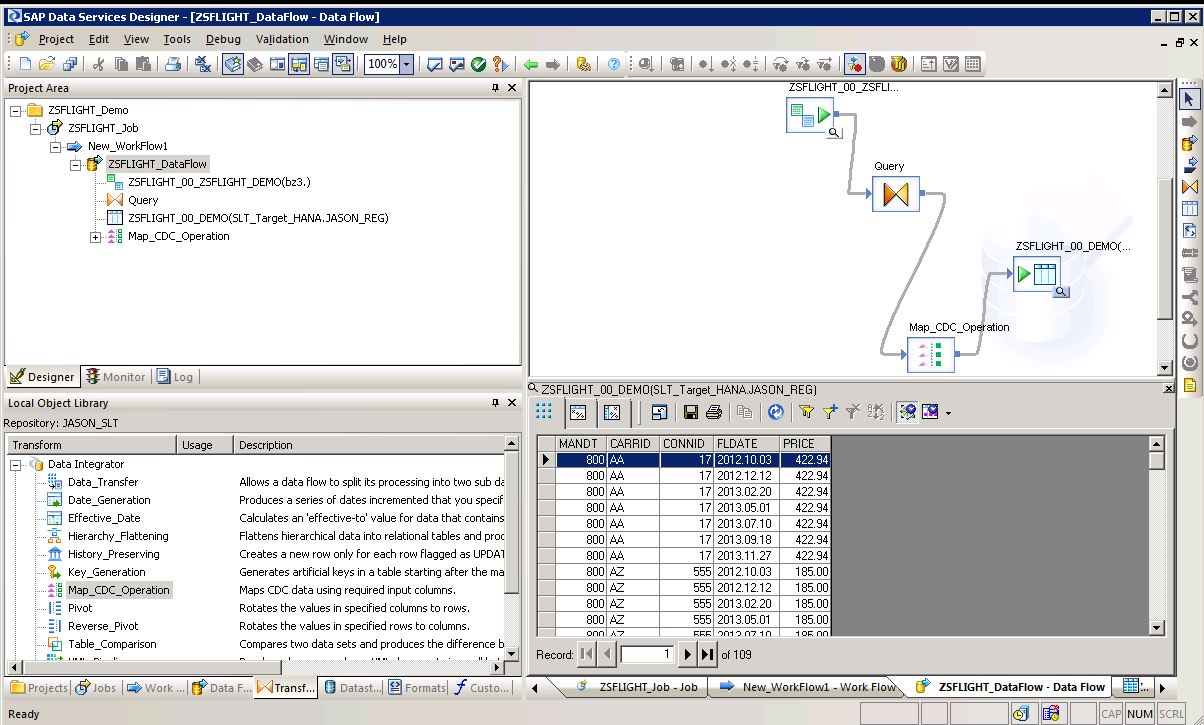

SAP LT Replication Server (SLT)
The product’s sweet spot is ABAP to ABAP realtime replication. Supported sources and targets are the databases ABAP runs on, Hana being one of them. Unlike the SDI ECCAdapter SLT is adding database triggers on the original source tables to capture the changes, which has downsides but also upsides.
For ABAP savvy users this is certainly the preferred option still. From a technical point of view 90% of the logic of SLT is what you would call an adapter in SDI. That is the reason why adding an SLT adapter to SDI would make so much sense.
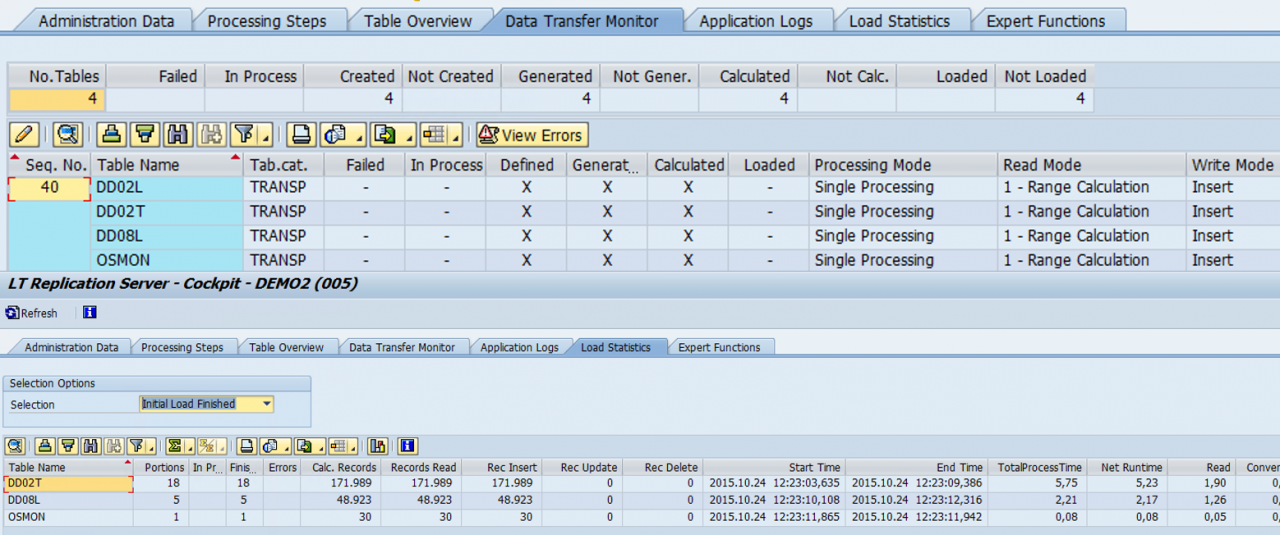
Sybase Replication Server
Main use case for SRS is a multi source/target replication. Supports the most common databases only.
Direct Extractor Connection
Had been a simple method to consume Extractors from Hana, completely replaced by SDA ABAPAdapter.
SAP Process Orchestration (SAP PI)
This tool does actually play in another league, it is an Enterprise Application Integration tool, not a Data Integration tool. Of course the difference between the two types is often marginal, e.g. if a customer master record consists of a single row in the application, there is no difference if you move the record (=row) or if you move the master record object (=row). It gets interesting in the complex cases, where one business object consists of many different types of Information.
SAP BW
With SAP BW on Hana the user is in a very comfortable position. For SAP extractors for example SAP BW has native support, why go another route? Hana data can be read as well. And for none-Hana data BW is using the Hana virtual tables, the SDI solution hence.
Therefore BW should not be considered an alternative but instead BW can utilize all other loading options to take advantage of those.
Hana SDA
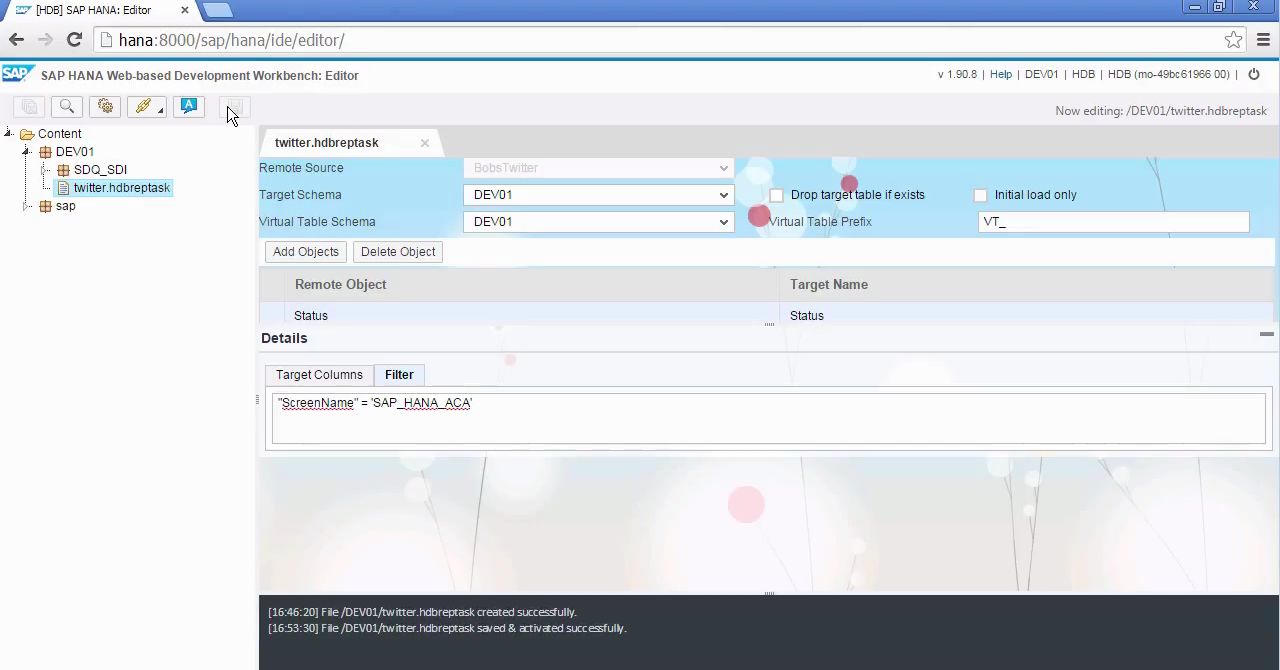
This feature enables the use of virtual tables in Hana. These are Hana objects that point to an external system to blend in the remote data in Hana. For example a SQL Server table CUSTOMER_MASTER can be blended in to Hana as virtual table V_CUSTOMER_MASTER. This virtual table is nothing else than a pointer to the remote table. So it does not store any data on the Hana side, all queries are forwarded to the remote system and the data retrieved.
SDA provides a set of adapters, all running in the Hana IndexServer and do use ODBC drivers. Nowadays the SDI provided adapters are used instead.
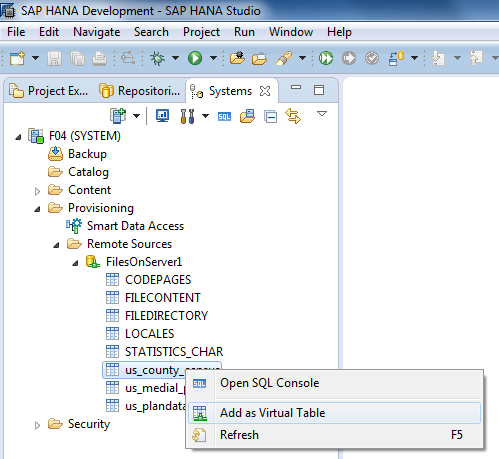
Hana SDI
This solution is a natural part of Hana and extends Hana SDA. Therefore all Hana products and applications can take full advantage of its capabilities just like SDI does utilize other Hana features.
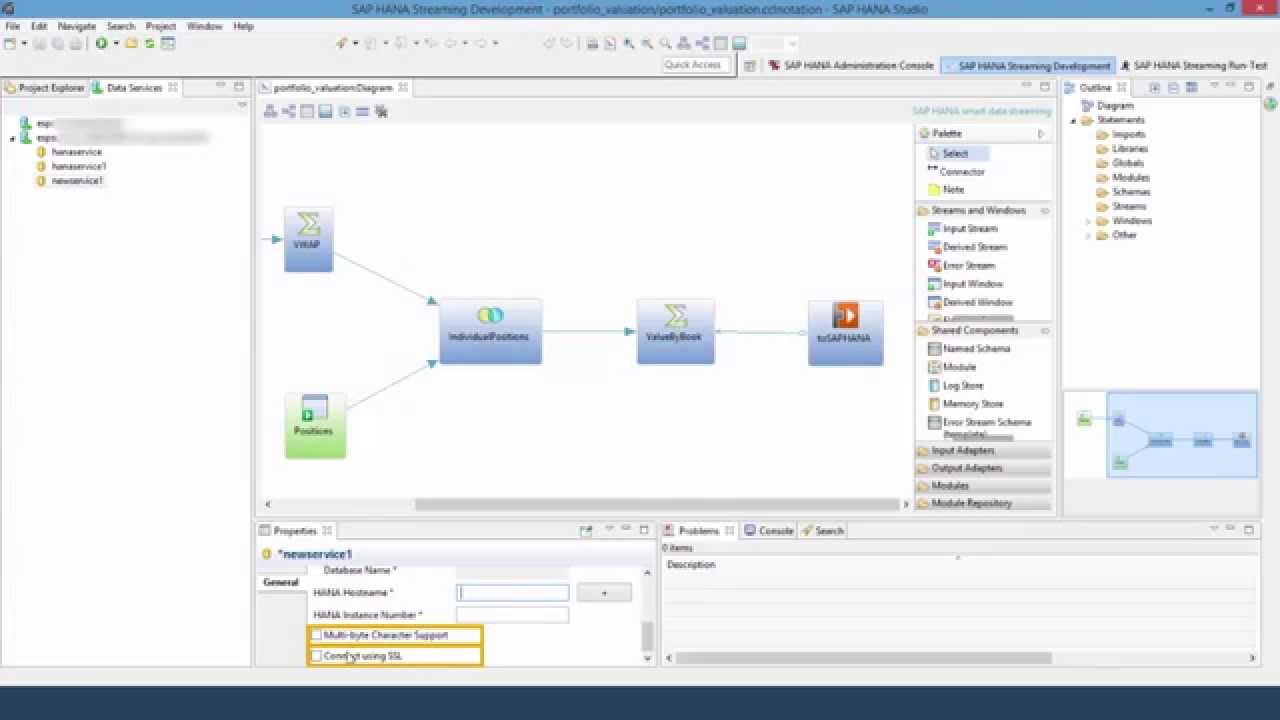
Hana SDS
Hana Smart Data Streaming again does actually compare to the other Data Provisioning options. Although it has adapters as well, its main goal is to aggregate the incoming stream of data, mostly by time slices. A good example is the streaming of WebLog changes. Instead of storing the billions and billions of raw weblog information in Hana, it might make more sense to extract key information from the raw data and store this information instead. How many users have viewed a web page within 10 minutes intervals?
Therefore the SDS provided adapters are more focused on these kinds of source which produce millions of rows per second and not database sources. It does support reading from databases as well but just to lookup master data, not to subscribe to database changes.
From:
https://blogs.sap.com/2016/07/05/the-various-data-provisioning-options-for-hana/
本文作者: GavinDong
版权属于: GavinDong博客
文章链接: https://gavindong.com/2288.html
如果使用过程中遇到问题,可 **点击此处** 交流沟通。
版权所有,转载时必须以链接形式注明作者和原始出处及本声明。
评论列表(2条)
选择:
SDI > SLT > SDS > BW
@ag:SDI + HANA + HANA Model + BO